Adventures In Computing: Text Message Author Prediction
I had to replace my phone recently, and while I was backing information up and evaluating possible replacements, it occurred to me that it would be pretty neat to do some data exploration on text messages. My family and I have a fairly active group chat, so there’s lots of data to look at. I started to wonder if there was enough information to create an algorithm for predicting the author of a text messages based on the content of the message.
Data Collection
Android doesn’t make it particularly easy to get at the data on your own phone, but there are a few methods to access text messages. I wrote a quick mobile app to export messages to a database, but while I was pondering how to correctly resolve threads and sent/received (since the data you can get using the native APIs doesn’t have explicit send-by and received-by fields) when I found SMS Import/Export, an open-source app that does exactly what I wanted! Mostly. I still had a couple of things to do to clean the data up.
Data Cleaning
The SMS Import/Export app produces a rather large (1.2GB for me) JSON file, which contains messages in this format:
{
"_id": "25594",
"thread_id": "18",
"address": "5059740155",
"date": "1654224388611",
"date_sent": "0",
"read": "1",
"status": "-1",
"type": "2",
"body": "<redacted>",
"locked": "0",
"sub_id": "1",
"error_code": "-1",
"creator": "com.google.android.apps.messaging",
"seen": "1",
"display_name": "Matt Pitts"
}
Not exactly the most convenient form for ingesting into a usable dataset (although it’s just fine for backups, which is the purpose of the app). Adding some complexity, a multipart message from the export file looks like this:
{
"_id": "10765",
"thread_id": "5",
"date": "1654883456",
"date_sent": "1654883456",
"msg_box": "1",
"read": "1",
"sub": "",
"sub_cs": "106",
"ct_t": "text/plain",
"m_type": "132",
"m_size": "0",
"tr_id": "proto:CkIKImNvbS5nb29nbGUuYW5kcm9pZC5hcHBzLm1lc3NhZ2luZy4SHBIaKhhNeHFNM2hLZ0l6UU9DcVNGRlpwSnR1VUE=",
"ct_cls": "135",
"locked": "0",
"sub_id": "1",
"seen": "1",
"creator": "com.google.android.apps.messaging",
"text_only": "1",
"sender_address": {
"_id": "39706",
"msg_id": "10765",
"address": "<redacted>",
"type": "137",
"charset": "106",
"display_name": "Karoline Eliza Pitts"
},
"recipient_addresses": [
{
"_id": "39705",
"msg_id": "10765",
"address": "<redacted>",
"type": "130",
"charset": "106",
"display_name": "Karoline Eliza Pitts"
},
{
"_id": "39707",
"msg_id": "10765",
"address": "<redacted>",
"type": "151",
"charset": "106",
"display_name": "Me"
}
],
"parts": [
{
"_id": "22526",
"mid": "10765",
"seq": "0",
"ct": "text/plain",
"name": "body",
"text": "<redacted>"
}
]
}
To get around this, I wrote a small Python script to parse the JSON and do a few things:
- Extract relevant fields like sender/receiver and timestamp
- Assemble full messages from multipart message bodies
- Normalize phone numbers
- Output to an easy-to-use CSV file
Step #3 was pretty important, since there’s no rule about having to
send fully qualified numbers in a text message header. So you might
have a number in three forms: country code + area code + number,
area code + number, or just number. Luckily, the excellent
phonenumbers library exists, and was very helpful in normalizing
phone numbers into the same format.
Data Augmentation
One problem that stood out is the significant imbalance of class-level data. Karoline isn’t nearly as active as Matt and I are:
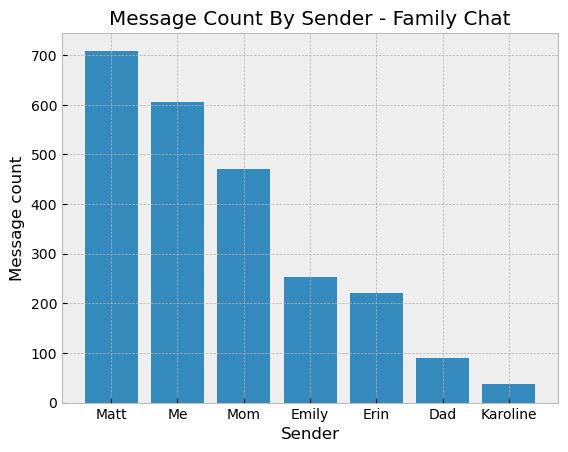
Which would make it hard to make an effective classifier if 98% of the
texts were “not-Karoline”. To mitigate this I read about dealing with
imbalanced data, and found
imbalanced-learn, an
sklearn-compatible package that has functionality for dealing with
imbalanced class representation. I read through the documentation for
the different strategies, and went with
SMOTEENN,
which handles both under- and over-sampling. It was pretty
straightforward to implement in code:
sampler: SMOTEENN = SMOTEENN()
features, labels = sampler.fit_resample(features, df["labels"])
features_train, features_test, labels_train, labels_test = train_test_split(
features, labels
)
Feature Extraction
For feature extraction I initially looked at bag-of-words, but wondered if applying it to a conversation would yield effective results, since a conversation by nature involves talking about the same things and using similar words. After thinking about it for a while, I decided to do an experiment: training a model with standard bag-of-words features and custom features I would extract with some custom code.
Bag-of-words
If you’re not familiar with bag-of-words features, it’s basically a reduction of a text document to the count of individual words, transforming them into a vector in feature space. To make sure words like “run” and “running” were treated as being the same word, I used a word stemmer from NLTK, and stripped out stop words like “the”, “and”, and “or”:
stemmer: PorterStemmer = PorterStemmer()
words: List[str] = stopwords.words("english")
df["cleaned"] = df["message_text"].apply(
lambda x: " ".join(
[
stemmer.stem(i)
for i in re.sub("[^a-zA-Z]", " ", x).split()
if i not in words
]
).lower()
)
The bag-of-words implementation came from scikit-learn’s CountVectorizer class:
vectorizer: CountVectorizer = CountVectorizer()
features = vectorizer.fit_transform(df["cleaned"], df["labels"])
Custom
For custom feature extraction, I decided to compute five specific features:
- The number of words in a message
- The number of sentences in a message
- The average word length
- The number of misspelled words (not that I’m accusing anyone of being a poor speller, but I tend to be fastidious about correct spelling in text messages, even if the meaning is clear, and since that’s not true of everyone, I thought it might be a useful feature)
- Lexical diversity
For the number of misspelled words, I used the pyspellchecker library, and computed all of the metrics in one pass:
sc: SpellChecker = SpellChecker()
for text in df["message_text"]:
words: List[str] = word_tokenize(text)
word_counts.append(len(words))
sentence_counts.append(len(sent_tokenize(text)))
if len(words) == 0:
mean_word_lengths.append(0)
else:
mean_word_lengths.append(np.mean([len(word) for word in words]))
misspelled_word_counts.append(len(sc.unknown(words)))
lexical_diversity_scores.append(len(text) / len(set(text)))
df["word_count"] = word_counts
df["sentence_count"] = sentence_counts
df["mean_word_length"] = mean_word_lengths
df["misspelled_word_count"] = misspelled_word_counts
df["lexical_diversity"] = lexical_diversity_scores
Model Selection
I used a grid search method to tune a pipeline containing a random forest classifier for each dataset. For the bag-of-words features, I used singular value decomposition to reduce the number of features that were being used and make it more computationally tractable. For the custom features, I scaled the data to make sure unique words or someone with a penchant for long words wouldn’t throw off the statistics.
Classification Results
No machine learning project is complete with eye candy charts and metrics!
Family Chat
Overall, it was a mixed bag. The bag-of-words model’s overall accuray was 92%, versus 90% for the custom features. Precision, recall, and F1 all showed relatively high scores.
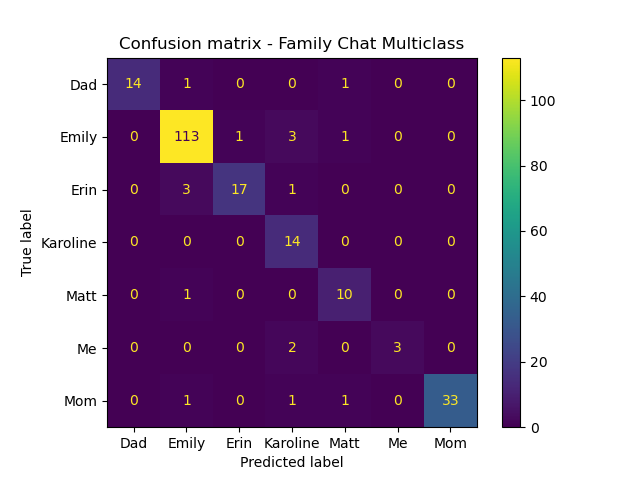
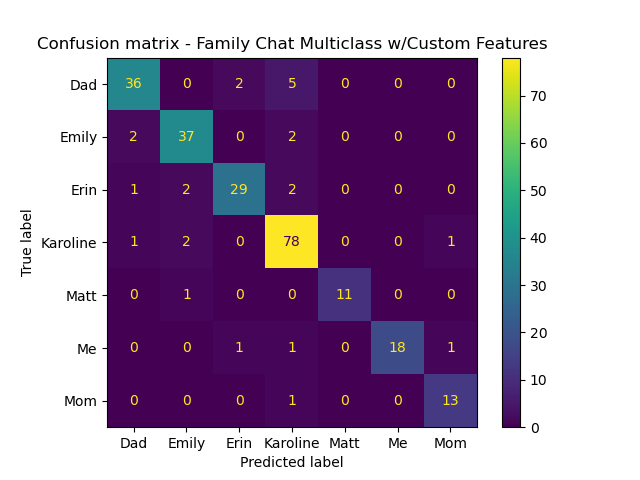
Other Chats
Once I had the process nailed down, I ran it against a couple of other text streams from my phone. For the text chat between Karoline and I, the models achieved fairly good performance. Accuracy with the custom features was ~98%, with similar F1 and precision scores.
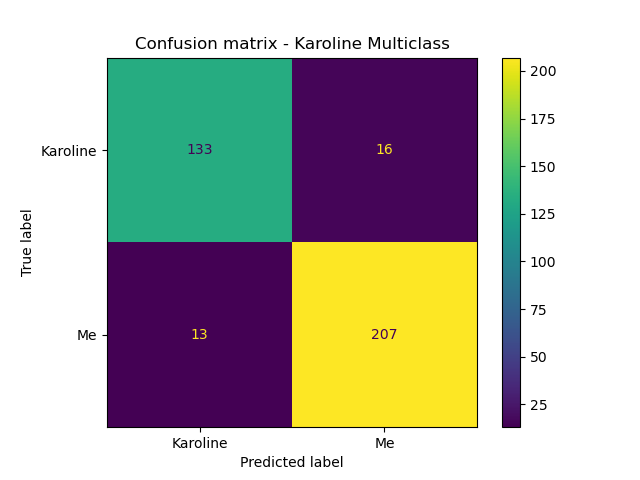
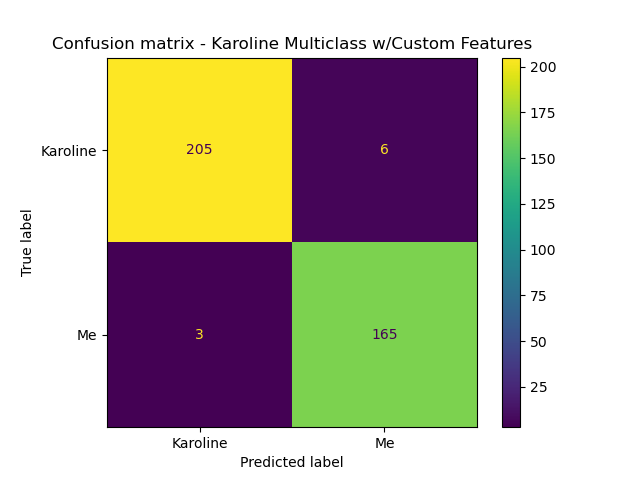
And a text chat with Matt and two friends of ours:
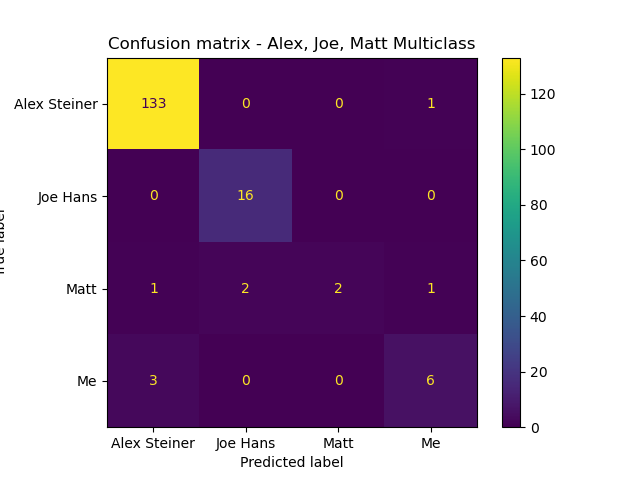
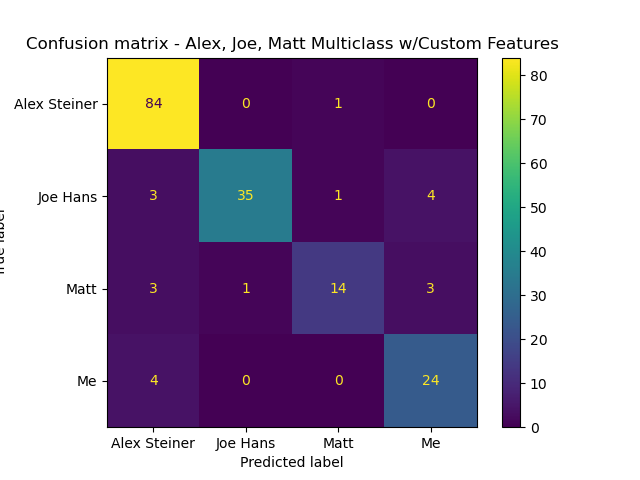
Conclusion
This was a pretty fun project. It was a good experience digging into Android internals, cleaning data, and automating a model training pipeline from ingest to prediction and analysis. I got familiar with a few new Python libraries for dealing with different data types and wildly imbalanced datasets.